Mistral AI Hackathon: Finding French Politicians at Scale
This project was completed as part of the SF Mistral AI Hackathon 2024 in collaboration with my wonderful teammates Vaibhav Kumar and Akhil Dhavala.
Overview
LLMs, like Mistral-Large, demonstrate strong out-of-the-box performance across a wide range of NLP tasks. However, leveraging LLM inference at scale remains cost constrained for web-scale datasets. We utilize Mistral-Large to generate labels for web data in the low-resource, high-cost-to-label task of fine-grained named entity recognition.
To extend this problem, we define a new fine-grained entity type, French politicians, and utilize our framework to rapidly generate synthetic data and train a downstream model. Scanning across a subset of the unlabeled dataset, we are able to identify 2174 mentions of French politicians compared to just 7 mentions in the labeled dataset.
Dataset
We utilize the "Politics" domain of the CrossNER dataset, an unlabeled corpora from Wikipedia. Further narrowing down, we select the task-level corpus type. The task-level corpus is explicitly related to the NER task in the target domain. To construct this corpus, the authors selected sentences having domain-specialized entities.
For the labeled portion, we use the CoNLL2003 data. Similar to CrossNER, we keep a small size of data samples in the training set for each domain since we consider a low-resource scenario.
| unlabeled | labeled | |
|---|---|---|
| # paragraph | 2.76M | 200 |
| # sentence | 9.07M | 541 |
| # tokens | 176.5M | 651 |
Entity types: politician, political party, election
Fine-tuning LLMs for Political NER
Our plan is to prompt Mistral-Large to generate additional synthetic labels and then fine-tune a Mistral-7B model on the expanded dataset for large scale inference. We use vector search and clustering to identify in-distribution unlabeled examples to maximize value for synthetic data generation.
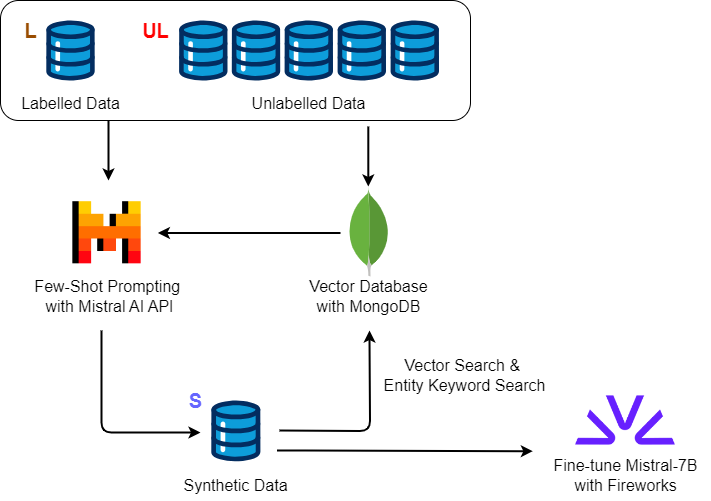
MongoDB Atlas Vector Search
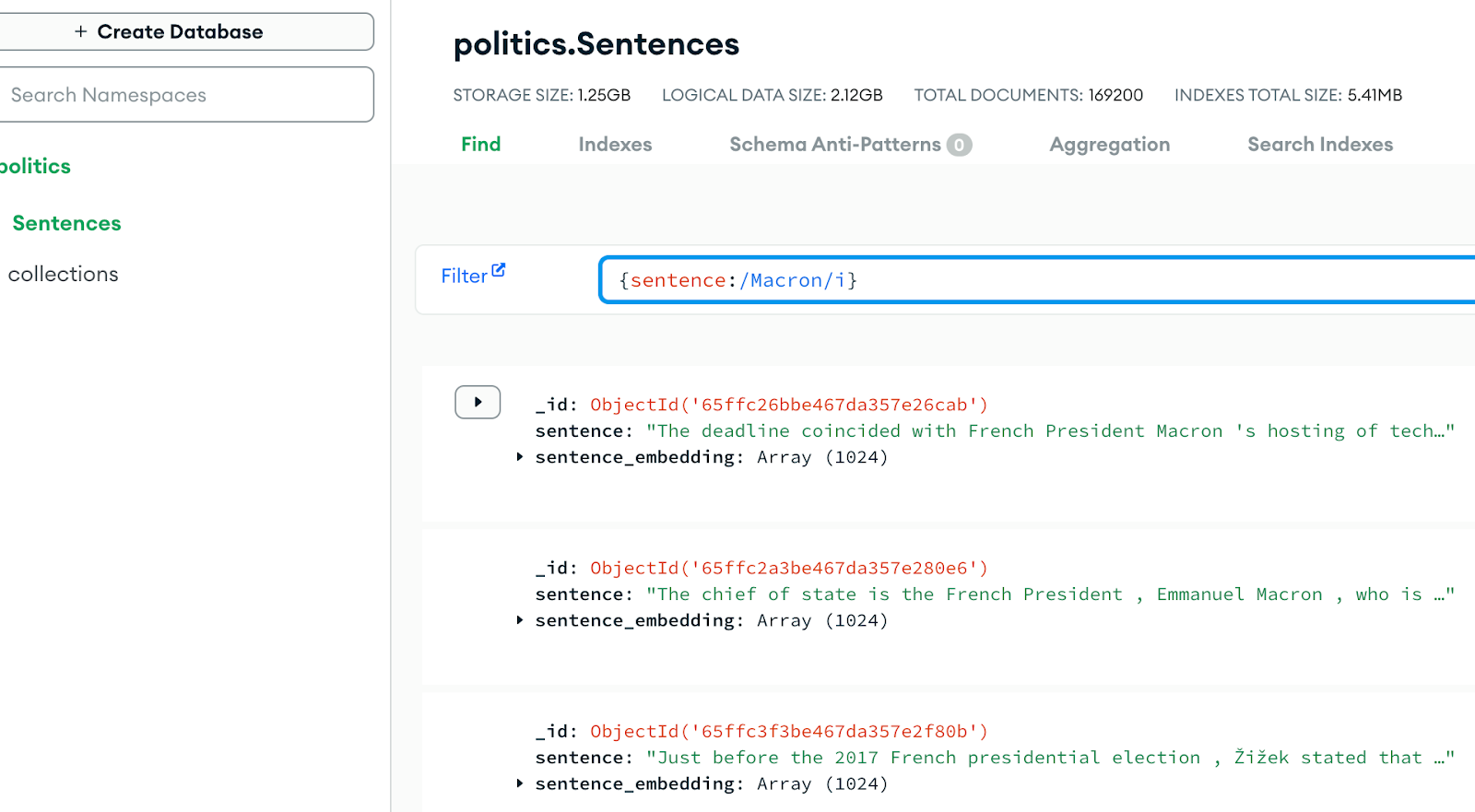
We use Mistral-Embed to generate embeddings for 169K unlabeled sentences in the task-level corpus. Then, we initialize MongoDB Atlas to store these embeddings as documents in a collection and added a Search Index to perform VectorSearch and retrieve similar sentences using cosine similarity.
Prompting Mistral-Large
Inspired by PromptNER, we prompt Mistral-Large with the following input:
Using 2-shot prompting, Mistral-Large achieves a macro-F1 of 0.68 across politician, political party, and election entity types.
| Entity | F1 Score |
|---|---|
| election | 74.02 |
| politicalparty | 62.78 |
| politician | 66.07 |
| Average (election, politicalparty, politician) | 67.62 |
Sampling Strategies
Uniform Sample
We use the 2-shot prompting approach to label a uniform sample of unlabeled sentences.
KNN Sample
Since a uniform sample over a vast unlabeled dataset might yield many examples that are out-of-distribution for the test set. We find the top 5 most similar unlabeled sentences using MongoDB VectorSearch to sentences in the test set. Then, we label this dataset by 2-shot prompting Mistral-Large.
Defining French Politicians and French Political Parties Entities
Supervised-NER models tend towards the recognition of a narrow and restricted set of coarse-grained entity types, such as person, organization, location. We tackle the challenge of extending these models to fine-grained, hierarchical, and intersection entity types. This class of entities is difficult to label as it often requires knowledge external to the text. And, intersectionality makes labeled data become even more scarce.
To solve this low base rate issue, initially we sample the task-level corpus for all unlabeled sentences that contain the keywords "france" and "french". Moreover, we filter out historical mentions by looking for sentences that include a year between 2012-2024.
We use Mistral-Large to score this for the newly defined "french politician" and "french political party" entities.
To expand this dataset further, we used KNN to get the top 5 most similar unlabeled examples to sentences with at least one French Politician or French Political Party entity. Moreover, we iterate on this dataset by sampling the unlabeled dataset for matches to all French Politician entities that appeared at least 3 in the initial scoring. Through three rounds of iterations, we expand the dataset for French politics:
| Method | Dataset Contribution |
|---|---|
| "France" and "French" keyword search (2012 - 2024) | 656 |
| KNN on sentences mentioning French politics | 683 |
| French politician entities keyword search | 949 |
| Total | 2288 |
We fine-tune a Mistral-7B model on these combined datasets. We apply this model across the unlabeled sentences to discover mentions of French Politicians and French Political Parties. Below are the top 10 mentioned French Politicians.
| French Politician | Frequency |
|---|---|
| Jacques Chirac | 132 |
| Nicolas Sarkozy | 92 |
| Charles de Gaulle | 91 |
| Emmanuel Macron | 68 |
| Marine Le Pen | 62 |
| Jean-Marie Le Pen | 56 |
| François Mitterrand | 52 |
| François Hollande | 48 |
| François Fillon | 48 |
| François Bayrou | 44 |
If you are interested in the code, checkout the Github french-politician-ner. Have a comment or question? Email me at dzhu319@gmail.com.